Dashboard
Introduction
Section titled “Introduction”What is the Dashboard?
Section titled “What is the Dashboard?”The Dashboard is the screen you land on when you open Testver at the root route /. Its job is to answer one question instantly: “How healthy are my tests right now?” It does this without you having to run anything — it reads the tests already written in your project and the history of past runs, then arranges that information into a grid of cards, charts, tables, and lists.
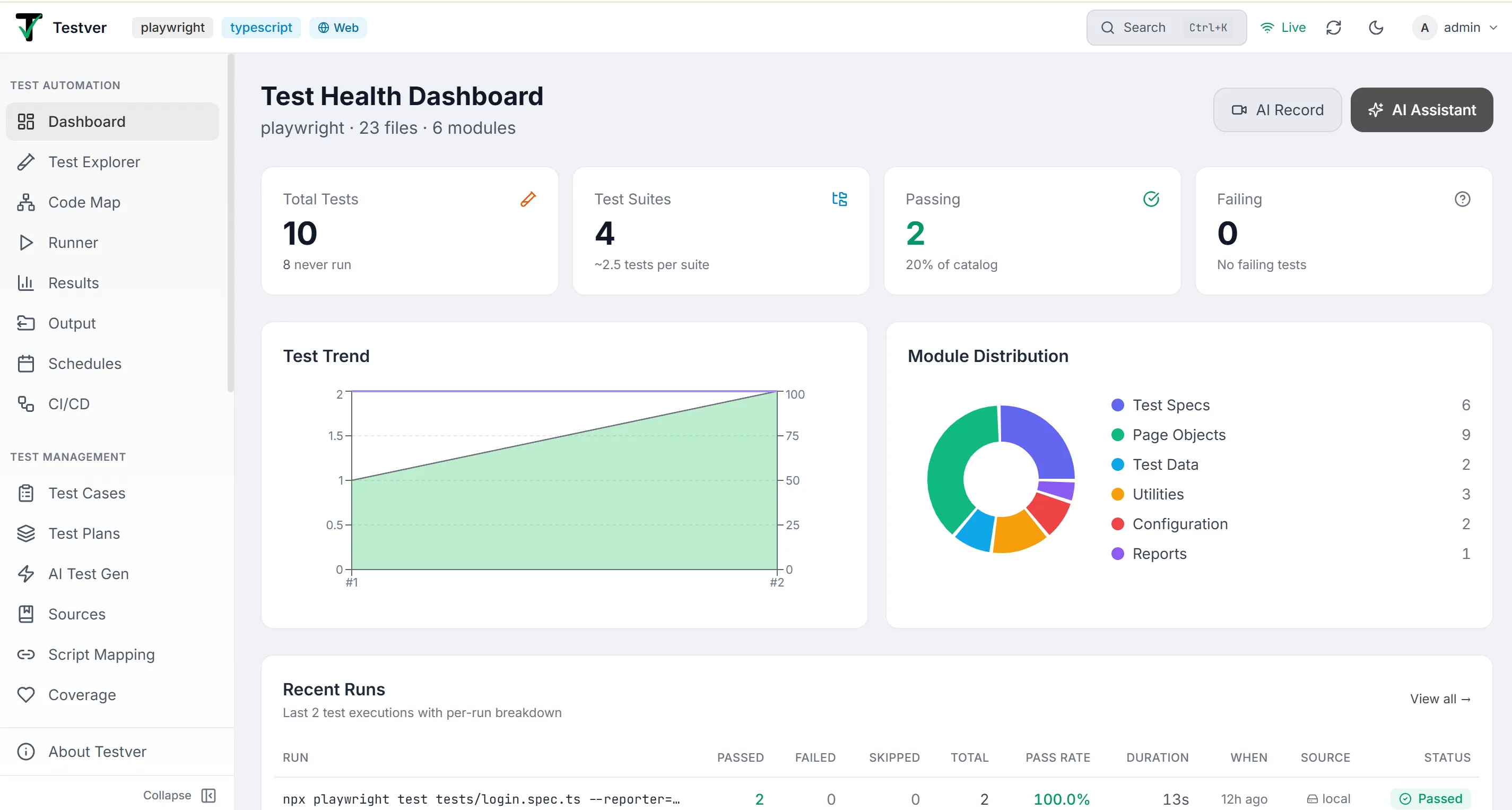
Think of it like the dashboard of a car. You don’t drive the car from the dashboard — the steering wheel and pedals are elsewhere — but a single glance tells you your speed, fuel level, engine temperature, and any warning lights. The Testver Dashboard works the same way: the Health cards are your gauges (how many tests, how many passing/failing), the Test Trend chart is like a trip history, Top Failures and Flaky Tests are your warning lights, and Recent Activity is the live ticker showing what just happened. You take action elsewhere (Run Tests, Test Explorer, AI), but you decide what to do from here.
Almost everything on the Dashboard is a shortcut. Cards and list rows are clickable and navigate you to the deeper screen where you can act — for example, clicking a failure takes you straight to that test in the Test Explorer. The Dashboard itself never changes your project; it only shows and links.
Who this guide is for
Section titled “Who this guide is for”- QA engineers and testers who want a daily health check before triaging or running tests.
- Developers who want to see whether their latest code changes broke any tests.
- Team leads / managers who want a high-level snapshot of pass rates and trends without reading raw logs.
- New Testver users who just opened the app and want to understand what every number, card, and chart on the home screen means.
- Anyone investigating a problem — the Dashboard surfaces the most failing and most unstable (flaky) tests first, so it is a natural starting point for triage.
Key terms
Section titled “Key terms”These terms appear throughout the Dashboard and the rest of this guide. Skim them once and the screen will read much more clearly.
| Term | What it means |
|---|---|
| Test | A single automated check written in your project (one test case). The Dashboard counts these as Total Tests. |
| Suite | A test file that contains one or more tests. Counted as Test Suites. Roughly, suites are files and tests are the cases inside them. |
| Catalog | The full set of tests Testver discovered by scanning your project’s source files (the Test Explorer view). The top Health cards are derived from the catalog, not from run history. |
| Run / Execution | One time you executed tests. A run produces a result with passed/failed/skipped counts, a duration, and a status. The Recent Runs table lists these. |
| Pass rate | The percentage of executed tests that passed in a run — passed ÷ total × 100. Shown per-run in Recent Runs and as a trend line in the Test Trend chart. |
| Passing (last) | A test whose most recent run finished green (status passed). The Passing card counts these across the catalog. |
| Failing (last) | A test whose most recent run finished red (status failed or error). The Failing card counts these. |
| Skipped | A test that was intentionally not executed in a run. Tracked separately and shown as subtext / a grey area in the trend chart. |
| Never run | A test in the catalog that has no recorded run yet (no last status). Shown as subtext on the Total Tests card. |
| Flaky test | A test that sometimes passes and sometimes fails without code changes — i.e. an unreliable test. Measured by a flakiness rate (a percentage). |
| Top failure | A test that has failed repeatedly. Ranked by failure count (how many times it failed) in the Top Failures card. |
| Module | A logical grouping of tests, usually a folder. The Module Distribution pie chart shows how your tests are spread across modules. |
| Local | A run executed on your own machine. Marked with a hard-drive icon labelled local in Recent Runs. |
| Cloud | A run executed on a remote cloud provider. Marked with a cloud icon and the provider name in Recent Runs. |
| Framework | The test framework Testver detected for your project (e.g. Playwright, Cypress, WebdriverIO). Shown in the header subtitle and per run. |
| Status | The outcome of a run: Passed, Failed, Running, or Cancelled. |
| Activity | A real-time event in your project — a file being created/modified/deleted, or a test run completing — shown in the Recent Activity feed. |
Where the numbers come from
Section titled “Where the numbers come from”The Dashboard draws from two distinct sources, and knowing which is which explains why some numbers stay stable while others change after every run.
- Catalog (Test Explorer scan) — The four top Health cards (Total Tests, Test Suites, Passing, Failing) come from scanning the actual test scripts in your repository. This is a stable view of your test portfolio that does not fluctuate with each execution. It refreshes automatically about every 30 seconds.
- Run history (results store) — The Test Trend chart, Recent Runs table, Top Failures, and Flaky Tests all come from the history of past executions stored by Testver. These change whenever you run tests.
- Live updates — Most widgets poll the server on a timer: the run list every ~10 seconds, the Test Trend and Top Failures every ~15 seconds, Flaky Tests every ~30 seconds, and the catalog every ~30 seconds. You do not need to refresh the page manually.
- Real-time activity — The Recent Activity feed is pushed live over a WebSocket. File edits and completed runs appear within moments, on top of an initial batch of recently persisted events loaded when the page opens.
- Project header data — The framework name, file count, and module count in the page header come from the current project’s scan info (the same project context shared across the app).
Getting Started
Section titled “Getting Started”Opening the Dashboard
Section titled “Opening the Dashboard”- Launch Testver and open the web UI in your browser.
- Make sure a project is loaded — the Dashboard reads from the currently selected project’s tests and run history.
- Click the first item in the left sidebar (the Dashboard / home link) or navigate to the root route
/. - The page fades in. Within a second or two the cards populate; widgets that depend on run history fill in as their data loads.
The screen layout
Section titled “The screen layout”The Dashboard is a single vertically-scrolling page with generous spacing. From top to bottom it is organized into a header strip, a row of health cards, a charts row, a full-width runs table, and a final row of three list cards.
| Area | Where | What it shows |
|---|---|---|
| Header & quick actions | Very top, full width | Page title, project subtitle (framework · files · modules), and two action buttons: AI Record and AI Assistant. |
| Health cards | Just below the header | Four equal cards: Total Tests, Test Suites, Passing, Failing. |
| Charts row | Below the cards (two columns on wide screens) | Left: Test Trend composed chart. Right: Module Distribution pie chart with a legend. |
| Recent Runs | Full-width below the charts | A table of the last few executions with per-run pass/fail/skip breakdown, duration, source, and status. |
| Bottom row | Last section (three columns on wide screens) | Top Failures, Flaky Tests, and Recent Activity side by side. |
At a glance
Section titled “At a glance”- Read the four cards first for the big picture: how many tests you have, how many suites, and how many are currently passing vs failing.
- Glance at the Test Trend chart to see whether pass rate is climbing or sliding over your recent runs.
- Check the Module Distribution pie to see where your tests are concentrated.
- Scan Recent Runs to confirm your latest execution and its outcome.
- Use Top Failures and Flaky Tests as your triage queue — they rank the worst offenders first.
- Watch Recent Activity to see file changes and run completions as they happen.
Header & Quick Actions
Section titled “Header & Quick Actions”The header is the strip across the very top of the Dashboard. On the left it identifies the screen and the project; on the right it offers two one-click shortcuts to the AI features.
Title and project subtitle
Section titled “Title and project subtitle”The large heading reads Test Health Dashboard. Directly beneath it is a smaller grey subtitle that summarizes the current project, in the form: framework · N files · M modules.
| Subtitle part | Meaning | Fallback |
|---|---|---|
| Framework | The detected test framework for the project (e.g. Playwright). | Shows Auto-detect when no framework is recorded. |
| N files | Total number of files Testver scanned in the project. | Shows the scanned count (0 if none). |
| M modules | Total number of modules (folder groupings) detected. | Shows the detected count (0 if none). |
Quick-action buttons
Section titled “Quick-action buttons”Two buttons sit on the right of the header. They are deliberately not duplicates of the sidebar — they are higher-value shortcuts to the AI tooling.
| Button | Icon | What it does | Navigates to |
|---|---|---|---|
| AI Record | Video camera | Starts recording a browser flow with AI assistance so you can capture a new test by demonstrating it. | /ai-record |
| AI Assistant | Sparkles | Opens the AI Assistant (the primary, highlighted action — filled accent colour). | /ai |
Health Cards
Section titled “Health Cards”Directly below the header is a row of four summary cards derived from the catalog (your actual test scripts), not from run history. This gives a stable portrait of your test portfolio. The row shows two cards per row on narrow screens and all four across on wide screens.
What each card shows
Section titled “What each card shows”| Card | Big number | Icon | Subtext |
|---|---|---|---|
| Total Tests | Count of all test cases in the catalog. | Orange test-tube. | Shows “N never run” (and ”, M skipped” if any). If every test has run with none skipped, it reads “All tests have executed.” |
| Test Suites | Count of test files containing tests. | Sky-blue folder tree. | ”~X tests per suite” (average), or “No suites detected” if none. |
| Passing | Count of tests whose last run passed. | Emerald check-circle (grey if zero). | ”P% of catalog” — passing as a percentage of all tests. Number turns emerald when above zero. |
| Failing | Count of tests whose last run failed or errored. | Red X-circle when failing > 0, otherwise a grey help-circle. | ”P% of catalog” when there are failures; “No failing tests” when none. Number turns red when above zero. |
How the numbers are computed
Section titled “How the numbers are computed”- Total Tests and Test Suites come directly from the catalog scan.
- Passing / Failing / Skipped / Never-run are tallied by walking every test in every suite and bucketing it by its last status.
- Average tests per suite is Total Tests ÷ Test Suites, rounded to one decimal.
- Percent of catalog (on Passing and Failing) is that count ÷ Total Tests, rounded to a whole number.
Loading and empty states
Section titled “Loading and empty states”| State | When it appears | What you see |
|---|---|---|
| Loading | While the catalog is being scanned for the first time (no tests counted yet). | All four cards show a long-dash placeholder for the number and the subtext “Scanning project…”. |
| Empty (no tests) | Scan finished but found zero tests. | All four cards show 0 with the subtext “No tests detected”. |
| Populated | Tests were found. | Real counts, coloured icons, and computed subtext as described above. |
Charts
Section titled “Charts”The charts row sits below the health cards and splits into two cards side by side on wide screens (stacked on narrow): the Test Trend chart on the left and the Module Distribution pie on the right.
Test Trend
Section titled “Test Trend”Test Trend plots the outcome of your recent runs (up to the latest 20) as a stacked area chart with an overlaid pass-rate line. It answers “are my runs getting healthier or worse over time?”
| Element | Axis | Meaning |
|---|---|---|
| Green area | Left Y-axis (count) | Number of passed tests in each run. |
| Red area | Left Y-axis (count) | Number of failed tests in each run (stacked on top of passed). |
| Grey area | Left Y-axis (count) | Number of skipped tests (stacked on top). |
| Purple line | Right Y-axis (0–100%) | Pass rate for each run. |
| X-axis labels | — | Run sequence labels #1, #2, … in chronological order (oldest to newest). |
- Hovering a point shows a tooltip with the passed / failed / skipped counts and pass rate for that run.
- The left axis auto-scales to test counts; the right axis is fixed to 0–100 for the pass-rate line.
- Up to 20 runs are shown.
Module Distribution
Section titled “Module Distribution”Module Distribution is a donut (pie) chart with a scrollable legend showing how many tests fall into each module. It tells you where your test coverage is concentrated.
| Element | Meaning |
|---|---|
| Donut segments | Each coloured slice is one module; the slice size is proportional to that module’s test count. |
| Legend rows | To the right of the donut: a colour dot, the module name, and its test count. The list scrolls if there are many modules. |
| Tooltip | Hovering a slice shows the module name and its value (count). |
Recent Runs
Section titled “Recent Runs”Recent Runs is the full-width table beneath the charts. It lists your latest executions (up to five) with a rich per-run breakdown, so you can see pass/fail counts without opening each run individually. It is driven by the same run-list data that powers the Test Trend chart.
Header and View all
Section titled “Header and View all”- The title is Recent Runs, with the subtext “Last N test executions with per-run breakdown” (N is the number of rows actually shown).
- A View all → link on the right navigates to the full results screen at
/results.
Columns
Section titled “Columns”| Column | Meaning | Notes |
|---|---|---|
| Run | The run’s human-readable label on top, with the underlying command in monospace below it. If there is no label, the command alone is shown. | Always visible. Truncates with the full value on hover. |
| Passed | Number of tests that passed in the run. | Always visible. Green; a long-dash if no summary is available. |
| Failed | Number of tests that failed. | Always visible. Red when greater than zero, grey when zero. |
| Skipped | Number of skipped tests. | Hidden on the smallest screens. |
| Total | Total tests in the run. | Always visible. |
| Pass Rate | Pass percentage for the run, one decimal. | Hidden on smaller screens. Coloured: emerald ≥ 90%, amber ≥ 70%, red below 70%. |
| Duration | How long the run took (e.g. ”45s”, “2m 5s”). | Always visible. Long-dash when unknown. |
| When | Relative age of the run (e.g. “5m ago”, “2h ago”, “3d ago”). | Hidden on the smallest screens. Hover shows the exact start time. |
| Source | Where the run executed: a cloud badge with the provider name, or a hard-drive “local” marker. | Hidden on smaller screens. |
| Status | A coloured pill: Passed, Failed, Running (animated spinner), or Cancelled. | Always visible. |
Clicking a row
Section titled “Clicking a row”Each row is clickable. Clicking anywhere on a run opens that specific run on the results screen, at /results?runId=<that run's id>. Rows highlight on hover and show a pointer cursor to signal they are interactive.
Empty state
Section titled “Empty state”Top Failures
Section titled “Top Failures”Top Failures is the first card in the bottom row. It lists the tests that have failed most often (up to five), ranked by failure count, so the worst offenders are at the top of your triage queue.
What each row shows
Section titled “What each row shows”| Element | Meaning |
|---|---|
| Red X icon | Marks the row as a failure. |
| Test name (top line) | The name of the failing test. |
| Error line (second line) | The last recorded error message, or “No error details” if none. Truncated, with the full text on hover. |
| Count badge (right) | How many times the test has failed, shown as “Nx” in red (e.g. “7x”). |
Clicking a failure
Section titled “Clicking a failure”Clicking a row deep-links you to that test in the Test Explorer so you can investigate it against the source, at /tests?file=<file>&test=<name>. If the recorded failure has no associated file (older data), it falls back to opening the Test Explorer at /tests without a filter.
Flaky Tests
Section titled “Flaky Tests”Flaky Tests is the middle card in the bottom row. It surfaces tests that pass sometimes and fail other times — the unreliable ones — ranked so you can stabilize them. It shows up to five, with a scrollable area if needed.
What each row shows
Section titled “What each row shows”| Element | Meaning |
|---|---|
| Amber warning triangle | Marks the row as a flaky test. |
| Test name (top line) | The name of the flaky test. |
| Status dots (second line) | Up to the last ten recent outcomes as small dots: green = passed, red = failed, grey = other/unknown. Reads left to right. Each dot’s status shows on hover. |
| Flakiness badge (right) | The flakiness rate as a percentage in amber (e.g. “40%”) — how unstable the test is. |
Clicking a flaky test
Section titled “Clicking a flaky test”Clicking a row deep-links to that test in the Test Explorer at /tests?file=<file>&test=<name>, landing you on the source file with the specific test selected. When file information is missing (older data), it falls back to /tests without a filter. Hovering a row shows the tooltip “Open <test name> in Results”.
Recent Activity
Section titled “Recent Activity”Recent Activity is the rightmost card in the bottom row — a live, scrolling feed of what is happening in your project. It combines an initial batch of recently persisted events with real-time updates pushed over a WebSocket, keeping the most recent events at the top (up to 30 retained).
Event types
Section titled “Event types”| Event | Icon | Text shown | Colour |
|---|---|---|---|
| File created | Folder-plus | ”<filename> created” | Emerald |
| File modified | File-edit | ”<filename> modified” | Sky blue |
| File deleted | Trash | ”<filename> deleted” | Red |
| Run passed | Check-circle | ”Run PASSED (Ns)” — duration in seconds when known | Emerald |
| Run failed | X-circle | ”Run FAILED (Ns)“ | Red |
Row anatomy
Section titled “Row anatomy”- A coloured icon on the left indicating the event type.
- The event text (e.g. “login.spec.ts modified” or “Run PASSED (12s)”).
- For file events, a second monospace line showing the full project-relative path (so you can tell which module the file belongs to). The full value appears on hover.
- For run-complete events triggered via an authenticated API, a small user badge (a person icon plus the username) showing who triggered the run. File-change events never carry a user.
- A timestamp on the right showing the event’s time (hours:minutes).
Filtering and limits
Section titled “Filtering and limits”- Noise from infrastructure folders is filtered out — events under paths like
.testver,.git,node_modules,dist,build,.next,coverage, and similar are never shown. - The feed keeps at most 30 events; older ones drop off the bottom.
- New events slide in at the top in real time.
Common Tasks (How Do I…?)
Section titled “Common Tasks (How Do I…?)”| I want to… | Do this |
|---|---|
| See how many tests I have in total | Read the Total Tests health card at the top. |
| Know how many tests are currently failing | Read the Failing health card (red when above zero). |
| See whether my test health is improving | Watch the purple pass-rate line in the Test Trend chart trend up or down. |
| Check the outcome of my last run | Look at the top row of the Recent Runs table and its Status pill. |
| Open a specific run’s full details | Click that run’s row in Recent Runs (goes to /results?runId=…). |
| See all my run history, not just five | Click View all → in Recent Runs (goes to /results). |
| Triage the worst failures | Start with Top Failures; click a row to open the test in the Test Explorer (/tests?file=…&test=…). |
| Find unstable tests to stabilize | Use Flaky Tests; the status dots and flakiness % show how erratic each one is. Click to open it in the Explorer. |
| See where my tests are concentrated | Read the Module Distribution pie and its legend. |
| Watch file edits and runs as they happen | Keep an eye on the Recent Activity feed. |
| Record a new browser flow with AI | Click AI Record in the header (goes to /ai-record). |
| Ask the AI Assistant for help | Click AI Assistant in the header (goes to /ai). |
| Find out who triggered a run | Look for the user badge on a Run PASSED/FAILED row in Recent Activity. |
Tips & Best Practices
Section titled “Tips & Best Practices”- Use the percent of catalog subtext on the Passing/Failing cards to gauge scale — “3 failing” feels very different at 3% of catalog versus 30%.
- Remember the health cards are catalog-based and stable, while the lower widgets are history-based and move after every run — a quiet trend chart doesn’t mean your catalog shrank.
- Let the widgets auto-refresh; there’s no need to reload the page. If a number looks stale, wait for the next poll cycle (10–30 seconds depending on the widget).
- Click through rather than copy values — every failure, flaky test, and run row deep-links to the exact screen where you can act.
- Watch the Source column in Recent Runs to confirm whether a run executed locally or in the cloud, which can explain duration differences.
Troubleshooting & FAQ
Section titled “Troubleshooting & FAQ”Why do the health cards show numbers but everything below says “No runs yet”? The cards come from scanning your test catalog, which exists as soon as you have test files. The Test Trend, Recent Runs, Top Failures, and Flaky Tests come from run history, which is empty until you actually execute tests. Run your tests once and the lower widgets populate.
Why don’t Passing + Failing add up to Total Tests? Because skipped tests and tests that have never run are excluded from both counts. Total Tests includes the whole catalog; Passing and Failing only count tests whose last status was green or red respectively.
The cards are stuck on “Scanning project…”. What’s wrong? The catalog scan hasn’t returned tests yet. On a large repo this can take a moment. If it persists, your project may have no recognizable test files, or the framework wasn’t detected — check the framework shown in the header subtitle.
Recent Runs is missing some columns. Columns like Skipped, Pass Rate, When, and Source are progressively hidden on narrow screens to keep the table readable. Widen your browser window, or scroll the table horizontally, to see them.
A run shows dashes (—) instead of pass/fail counts. That run’s result doesn’t include a detailed summary (it can happen with older runs or certain servers). The row still shows the command, duration, and status; open it via the row click for whatever detail exists.
A run is stuck on “Running” with a spinner. That run is still in progress. The list refreshes about every 10 seconds, so the status updates automatically once the run finishes or is cancelled.
The Module Distribution chart is empty. No modules were detected. Organize your test files under module folders, and once a scan picks them up the pie and legend will appear.
Recent Activity isn’t updating live. The feed relies on a real-time WebSocket connection. If it isn’t showing new file edits or run completions, the live connection may be down — reload the page to re-establish it. Note that events under infrastructure folders (like node_modules or .git) are intentionally never shown.
A failure or flaky test opened /tests with no test selected when I clicked it. That entry has no recorded source file (usually older data), so the Dashboard falls back to opening the Test Explorer without a filter. You can locate the test manually from there.
Do the AI Record / AI Assistant buttons start anything? No. They only navigate to /ai-record and /ai respectively; the actual recording or conversation begins on those screens.
Related
Section titled “Related”- Test Explorer — drills into the test catalog.
- Results — full run history.
- Defects — bug tracker.
- Reports — custom dashboards beyond this home view.